Sorting by Relative Popularity
To drive up user engagement at theScore, we recently introduced an onboarding screen that's shown when you open the app for the first time. First, you get a list of sports teams that are popular in your area, and the option to subscribe to some of them:
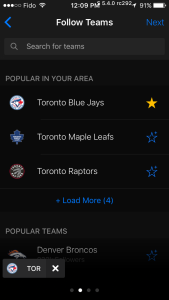
Now based on the teams you choose, it would be nice to also recommend some players for you to follow. So how would one go about choosing which players to recommend out of all those teams?
Looks like I'm gonna have to sort user content again! last time, I sorted user posts by "interestingness"; this time around I'll be sorting players from a set of sports teams. Once again we'll look at why sorting things based on popularity alone is a bad idea, we'll get a primer on standard deviation, and finally a bit of scripting to put it all together.
Let's assume we have three six-player teams, where each player has the following number of subscribers:
big_team_1:
1. 100 000
2. 110 000
3. 90 000
4. 80 500
5. 140 000
6. 140 500
big_team_2:
1. 120 000
2. 250 000
3. 180 000
4. 135 000
5. 157 000
6. 202 000
small_team:
1. 3 000
2. 100
3. 234
4. 301
5. 250
6. 400
Now let's consider some properties we want from our algorithm:
A compute-once, static value: we don't want to run our algorithm on every user. We want to give each player in our database a static
recommendation_score; a numeric value that is cheap to index.Simple: the algorithm should be simple and use elementary methods. Recommending players is a small part of the app; there should be little code maintenance involved.
Variety: The purpose of the onboarding process is to get you engaged, so we want to recommend a variety of players from different sports and leagues.
The Naive Approach
NOTE: Even though our actual script was written in Ruby, I will be using the Julia programming language for all my examples. You can find the complete implementation at the bottom of this post.
The first obvious solution is to simply sort players by their subscription_count. The more popular the player, the more recommendable he is. Here is our naive sorting function:
function naive_sort(teams)
Base.sort(
[[team.players for team in teams]...],
by=x -> x.subscribers,
rev=true
)[1:5]
end
Which yields:
5-element Array{PlayerRecommender.Player,1}:
Big Team 2 Player | subscribers: 250000
Big Team 2 Player | subscribers: 202000
Big Team 2 Player | subscribers: 180000
Big Team 2 Player | subscribers: 157000
Big Team 1 Player | subscribers: 140500
The problem with this approach is that we only get results from the most popular teams. So if you're a fan of both a very popular NFL team and another team that is not as popular (your local basketball team, perhaps), even the least popular player from the NFL team will be recommended to you, whereas the most popular player from your favorite local basketball team will not show up in your list at all!
A Better Approach
What are we really looking for?
Well, I think the players we want to recommend are not necessarily the ones who are most famous, but rather, the ones who are most popular compared to the rest of their team, regardless of how popular that team is (we already know you're a fan of the team or you wouldn't have subscribed to it in the first place).
In other words, we want an algorithm that answers the following question:
Which players deviate the most in popularity from the rest of their team?
Luckily, there's a mathematical tool for figuring out just this: standard deviation.
Standard Deviation tl;dr
Standard deviation is a pretty straight-forward concept: Take a set of values, and figure out the average value for that set (also known as the arithmetic mean). The standard deviation simply tells us by how much the value of the typical element in our set deviates from the average.
The mathematical representation of this calculation is:
$$ s_N = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \overline{x})^2} $$
Where \(N\) is the population size, and \(\overline{x}\) is the arithmetic mean, which itself is represented by:
$$ \overline{x}_N=\frac{1}{N}\sum_{i=1}^{N} a_i $$
For example, the following two sets have the same average value, but clearly the values are spread out differently:
close_to_average = [11,8,9,12]
spread_out = [0,1,19,20]
average(close_to_average) == 10
average(spread_out) == 10
standard_deviation(close_to_average) == 1.59
standard_deviation(spread_out) == 9.51
Thus we arrive at our simple scoring function. All we need to do is find players whose deviation from the average is substantially higher than that of their teammates:
function recommend(player, team)
player_dev = player.subscribers - team.average
if player_dev == 0
player.recommendation_score = 0
else
player.recommendation_score = player_dev / team.std_dev
end
end
Using this scoring function on our original teams, we get the following results:
5-element Array{PlayerRecommender.Player,1}:
Small Team Player | subscribers: 3000 | score: 2.2276261544470644
Big Team 2 Player | subscribers: 250000 | score: 1.749555170961297
Big Team 1 Player | subscribers: 140500 | score: 1.3134034577576315
Big Team 1 Player | subscribers: 140000 | score: 1.291753950212176
Big Team 2 Player | subscribers: 202000 | score: 0.6445729577225832
Much better. This time around, our top player actually has the least number of subscribers, but this makes sense, because even though he belongs to a team that is not very popular, his subscription count is tenfold that of his teammates; clearly someone to keep an eye on! (Perhaps a rising star in a college league? Certainly wouldn't want our recommendation script to ignore that one.)
Limitations
This algorithm has many limitations.
New players won't be very well represented (they will by nature have low subscription counts).
All-star teams might result in nobody being particularly recommendable. Though this one might be less of a problem: thanks to our good ol' friend the bell curve, even among rare anomalies, there are rare anomalies.
While there are ways to address these limitations and improve the accuracy of the algorithm (for example, taking into account the rate of change in subscription_count), one has to remember the purpose of this feature: to drive up user engagement during onboarding. Is the added complexity of such changes worth the minimal improvement in the recommendations?
Point is, it's Friday night and I should go out for a beer now. I'm also looking forward to testing out the enormous Chinese fermentation jug I bought yesterday. It looks something like this, but a LOT bigger:

And it was only $30. What a bargain.
Here is the code used in these examples (working as of Julia 0.4.1). Our actual code at theScore is in Ruby.
module PlayerRecommender
export Team, Player, big_team_1, big_team_2, small_team
export naive_sort, sort
type Player
subscribers::Int
team::AbstractString
recommendation_score::Float64
function Player(subscribers)
new(subscribers, "", 0.0)
end
end
# Pretty print Player
function Base.show(io::IO, p::Player)
print(io, "$(p.team) $(typeof(p)) | subscribers: $(p.subscribers) | score: $(p.recommendation_score)")
end
type Team
players::Array{Player}
std_dev::Float64
average::Float64
name::AbstractString
function Team(name, players)
for p in players
p.team = name
end
new(players, 0.0, 0.0, name)
end
end
function naive_sort(teams)
Base.sort(
[[team.players for team in teams]...],
by=x -> x.subscribers,
rev=true
)[1:5]
end
function sort(teams)
map(set_subscriptions_avg, teams)
map(std_dev, teams)
map(recommend, teams)
Base.sort(
[[team.players for team in teams]...],
by=x -> x.recommendation_score,
rev=true
)[1:5]
end
# Private
function average(xs)
reduce(+, xs) / length(xs)
end
function dev_from_average(xs, average)
map(x -> x - average, xs)
end
function recommend(team)
map( x -> recommend(x, team), team.players)
end
function recommend(player, team)
player_dev = player.subscribers - team.average
if player_dev == 0
player.recommendation_score = 0
else
player.recommendation_score = player_dev / team.std_dev
end
end
function set_subscriptions_avg(team)
team.average = average([p.subscribers for p in team.players])
end
function squares(xs)
map(x -> x * x, xs)
end
function std_dev(team)
team.std_dev = std_dev([p.subscribers for p in team.players], team.average)
end
function std_dev(xs, average)
sqrt(reduce(+, squares(dev_from_average(xs, average))) / length(xs))
end
function subscriptions_avg(team)
team.average = average(float([x.subscribers for x in team.players]))
end
end